This is a template for analysing, cleaning, and extracting features for sleep data collected by a wearable device. It is an extension of the general template where full details of the pipeline used here can be found. The following assumptions are made about the dataset:
This template begins with some data analyses to gain a deeper understanding of the dataset. The information gained from the data analysis is then used to decide how to clean the data and extract features. These features include the average heart rate per day, hour, or minute and some metadata features that describe the data quality.
All functions can be further tailored to your data in two ways:
This template uses example data from Apple watch, with the filename active_apple_healthkit_sleep_stage. However, it should be useful for any type of wearable sleep data and can be adjusted by changing the variables set in the code snippets.
Data Analysis¶
First, we will import all the necessary functions and get the list of data files:
import os
import sys
from pathlib import Path
import matplotlib.pyplot as plt
import pandas as pd
from IPython.display import HTML, display
sys.path.insert(
0, str(Path().resolve().parent / "src")
) # Set the path to the src folder so that we can import the functions from there
import additional_funcs
import all_field_summaries
import calculate_durations
import clean_and_extract_features
import feature_extraction
import helper_funcs
import timestamps_check
base_dir = Path.cwd().parent # go up one level from where you're running
folder_path = base_dir / "example_data"
folder_path_str = str(folder_path) + "/"
# Set input variables
Folder_structure = 1 # This should be either 1 or 2 (see above)
csv_name = "active_apple_healthkit_sleep_stage" # The standard name for the csv that contains this data
site_list = ["test"] # The names of the subfolders for each site
input_folder = folder_path_str # The folder that contains all the site subfolders
# Get a list of the paths to each file to be included in this analysis
files_list = helper_funcs.get_file_paths(
input_folder, csv_name, Folder_structure, site_list
)3 files found
Summarise Fields¶
The purpose of this function is to get a general idea of the distribution of values in any fields of interest across all the data. This will include the sleep stages field to check the full range of sleep stages included. It may also include any other fields you wish to analyse, such as efficiency to see if the range given is realistic. Further details about this function are described in the general template.
Below is an example of this tool being run on active_apple_healthkit_sleep_stage data. To tailor this to your data, adjust the following variables:
# Edit this dictionary if you need to filter the data.
filter_dictionary = {
# If you wish to only keep datapoints with certain values on specific rows, edit this
# dictionary and set filter_dict in the function below to filter_dictionary. The keys
# here are the names of the columns you want to filter by, and the values are the list
# of acceptable entries for that column.
"col1": [1, 3, 5],
"col2": ["A", "C"],
}
# Call Summarise_fields
df = all_field_summaries.Summarise_fields(
files_list=files_list,
time_stamp="value.time", # The name of the column that contains the timestamp.
fields=[
"value.stringValue"
], # We want to analyse 'value.stringValue' as this field reports sleep stages.
filter_dict=None, # No filtering required
df_adjustment_args=[None], # No adjustments neccesary for this data type.
)
# Then display the results
df = df.round(
2
) # rounds the numbers for ease of viewing, may need to be adjusted depending on data.
html_table = df.to_html(index=False)
styled_html = f"<div style='font-size:12px'>{html_table}</div>"
display(HTML(styled_html))This function analyses the time gaps between each datapoint and the durations of datapoints, in an effort to understand what the expected sampling frequency of the data is. The mean, median, mode and range are given. Also included is the number of datapoints that are equal to the mode, within a (adjustable) threshold of the mode, or more than the same threshold below the mode. These are included to get an idea of whether one particular sampling frequency dominates, if there is an intended sampling frequency then the former two are likely to be high and the latter is likely to be low.
Below is an example of this function being run for active_apple_healthkit_sleep_stage data. To tailor this to your data, adjust the following variables:
# Edit this if you need to filter the data
filter_dictionary = {
# If you wish to only keep datapoints with certain values on specific rows, edit this
# dictionary and set the filter_dict variable below to 'filter_dictionary'
# The keys of this dictionary should be the names of the columns you want to filter by,
# and the values should be a list of allowed values for that column (rows with any other
# values in this column will be filtered out)
"value.stringValue": [
"sleep.awake",
"sleep.light",
"sleep.rem",
"sleep.deep",
"sleep",
],
}
# Run investigate_frequencies
df = calculate_durations.investigate_frequency(
files_list=files_list,
thresh=1, # The threshold used when investigating closeness to mode.
timestamp_col="value.time", # Name of timestamp column
end_time_col="value.endTime", # Name of end time column.
duration_col=None, # There is no duration column
convert_to_unix=None, # The data is already in unix seconds
filter_dict=filter_dictionary, # This is used to filter out datapoints reporting 'sleep.inbed'
df_adjustment_args=[None], # No adjustments neccesary for this data type.
)
# Display results
html_table = df.to_html(index=False)
styled_html = f"<div style='font-size:14px'>{html_table}</div>"
display(HTML(styled_html))You can check whether the durations and time gaps seem sensible. You may which to experiment with different values of the variable thresh to get an idea of the expected minimum time gap to inform choice of STG later. In this case, the number under mode went down considerably when the thresh was increased past 30, suggesting that 30 is the minimum expected gap, and therefore a suitable value for the STG.
As well as checking the duration and gaps between each individual datapoint, you may also wish to check the size of blocks of data points. This is because in the feature extraction stage we assume that datapoints come in blocks (where one datapoint ends where the next one begins) corresponding to individual sleep episodes. To get an idea of whether your data follows this structure you can use the below code to see the distribution of block lengths. To tailor this to another data type, adjust the following variables:
filter_dictionary = {
# If you wish to only keep datapoints with certain values on specific rows, edit this
# dictionary and set the filter_dict variable below to 'filter_dictionary'
# The keys of this dictionary should be the names of the columns you want to filter by,
# and the values should be a list of allowed values for that column (rows with any other values in this
# column will be filtered out)
"value.stringValue": [
"sleep.awake",
"sleep.light",
"sleep.rem",
"sleep.deep",
"sleep",
],
}
all_block_durations = additional_funcs.investigate_sleep_blocks(
files_list=files_list,
timestamp_col="value.time", # The timestamp column
sleep_level_col="value.stringValue", # The column that reports sleep stages
duration_col=None, # No duration column given
end_time_col="value.endTime", # The end time column
convert_to_unix=None, # This data is already in unix seconds
filter_dict=filter_dictionary, # This is used to remove datapoints with 'sleep.inBed'
)
plt.hist(all_block_durations, edgecolor="black")
# Add labels and title
plt.xlabel("Duration of sleep episodes (hours)")
plt.ylabel("Frequency")
# plt.xticks(range(0, 1401, 100))
plt.title("Sleep blocks")
# Show plot
plt.show()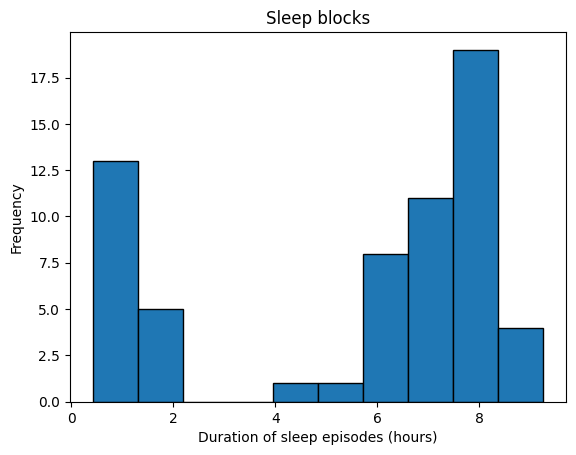
If the duration peaks at roughly 8 hours this suggests that the data has the expected blocks format.
Check Timestamp Errors¶
This function checks the frequencies of various timestamp errors. These include:
The threshold used to define STG errors (timegap_threshold) should be the minimum amount of time expected between datapoints. The results from the investigate_frequency function above may be useful in informing choice of this threshold. The amount records are allowed to overlap by (EAS_threshold) should be set based on what is a reasonable overlap considering the typical duration of a datapoint, again choice of the threshold may be informed by the results from the investigate_frequency function above.
Below is an example of this tool being run for active_apple_healthkit_sleep_stages. To tailor this to your data, adjust the following variables:
filter_dictionary = {
# If you wish to only keep datapoints with certain values on specific rows, edit this
# dictionary and set the filter_dict variable below to 'filter_dictionary'
# The keys of this dictionary should be the names of the columns you want to filter by,
# and the values should be a list of allowed values for that column (rows with any other values in this
# column will be filtered out)
"value.stringValue": [
"sleep.awake",
"sleep.light",
"sleep.rem",
"sleep.deep",
"sleep",
],
}
df = timestamps_check.check_timestamp_errors(
files_list=files_list,
EAS_threshold=5, # The threshold above which that datapoint will be counted as a EAS-OT.
timegap_threshold=30, # The threshold below which a time gap will be counted as a STG
measurement_cols=[
"value.stringValue"
], # a list of all measurement columns to be included.
timestamp_col="value.time", # Name of timestamp column
end_time_col="value.endTime", # Name of end time column.
duration_col=None, # No duration column given for this data
convert_to_unix=None, # This data is already in unix seconds
filter_dict=filter_dictionary, # No fields need filtering so leave as None.
df_adjustment_args=[None], # No adjustments neccesary for this data type.
output_folder="../output/sleep/time_stamp_check_files/", # A folder where outputs are stored
site_col="key.projectId", # Site column name
participant_ID_col="key.userId", # participant ID column name
)
html_table = df.to_html(index=False)
styled_html = f"<div style='font-size:14px'>{html_table}</div>"
display(HTML(styled_html))If the frequency of timestamp errors is higher than acceptable, then you may wish to repeat with one column at a time in the measurements_col list to pinpoint the source of the issue. It may also be useful to try leaving out the end time or duration column to investigate whether it is the measurement or duration that is changing for RT+CM and STG+CM. The files in the output folder can be useful for investigating these errors further and finding potential explanations.
Cleaning and feature extraction¶
The below code cleans the data, extracts metadata features, and then extracts summary features (such as total sleep time per day) from the sleep stages field.
The first step of the data cleaning and feature extraction process below is calling the function get_timestamp_errors_and_clean, which produces a cleaned version of each input file and calculates some metadata features including the number of RT+CM, STG+CM, STG-CM, and EAS errors in that interval (e.g. minute/hour/day), the total number of datapoints in the interval after cleaning, and the total number of datapoints with at least one timestamp error. For full details on how the data is cleaned, see general template. In the example below we use active_apple_healthkit_heart_rate, to tailor this function to your data, adjust the following variables:
We use first for the meas_agg variable, as the measurement values are strings so numeric methods such as mean or sum are not possible.
We next use the function get_sleep_features on the cleaned data to extract the following features:
This function requires the following variables to be set:
# TODO Add options for a range of input and output file structures and csv compressions
# TODO fix warning from sleep duration extraction function
output_folder = "../output/"
data_type = "active_apple_healthkit_sleep_stage"
interval = "D" # We want daily features
interval = "D"
filter_dictionary = {
# If you wish to only keep datapoints with certain values on specific rows, edit this
# dictionary and set the filter_dict variable below to 'filter_dictionary'
# The keys of this dictionary should be the names of the columns you want to filter by,
# and the values should be a list of allowed values for that column (rows with any other values in this
# column will be filtered out)
"value.stringValue": [
"sleep.awake",
"sleep.light",
"sleep.rem",
"sleep.deep",
"sleep",
],
}
for file_path in files_list:
# Get ready to save output folder
participant, site = helper_funcs.get_participant_and_site(file_path)
os.makedirs(output_folder + site, exist_ok=True)
os.makedirs(output_folder + site + "/" + participant, exist_ok=True)
# Read in the csv as a df
try:
if file_path[-3:] == "csv":
df = pd.read_csv(file_path)
if file_path[-3:] == ".gz":
df = pd.read_csv(file_path, compression="gzip")
except Exception:
print(file_path + " file cannot be read")
continue
# Get cleaned version of the raw data and extract metadata features, then save to output folder
cleaned_df, features = clean_and_extract_features.get_timestamp_errors_and_clean(
df=df,
interval=interval,
time_stamp_col="value.time", # The timestamp column
measurement_col="value.stringValue", # The sleep stages column
EAS_thresh=1,
STG=30, # The STG value
STG_fix=True, # We want to fix STG errors in the cleaned data files
meas_agg="first", # Take the sleep stage of the first datapoint when cleaning RT+CM and STG+CM
end_time_col="value.endTime", # The end time column
duration_col=None, # No duration column needed
convert_to_unix=None, # The data is already in unix seconds
filter_dict=filter_dictionary, # We want to filter out 'sleep.inbed' from the sleep stages column
included_errors=[
"RT+CM",
"STG-CM",
"STG+CM",
"EAS",
], # Change from default to include EAS
)
# Extract features from cleaned_df
if len(cleaned_df) > 0:
sleep_features = feature_extraction.get_sleep_features(
cleaned_df,
timestamp_col="value.time", # The timestamp/ start time column name
sleep_stage_col="value.stringValue", # The name of the measurement column that reports sleep stage
awake_string="sleep.awake", # The string in the sleep stage column that represent awake periods
sleep_stages=[
"sleep.rem",
"sleep.light",
"sleep.deep",
], # A list of all non-awake sleep stages
interval=interval,
end_time_col="value.endTime", # The end time column
duration_col=None, # There is no duration column
)
sleep_features.to_csv(
output_folder
+ "/"
+ site
+ "/"
+ participant
+ "/"
+ data_type
+ "_"
+ interval
+ "_features.csv"
)
# Save outputs
cleaned_df.to_csv(
output_folder
+ "/"
+ site
+ "/"
+ participant
+ "/"
+ data_type
+ "_cleaned.csv"
)
features.to_csv(
output_folder
+ "/"
+ site
+ "/"
+ participant
+ "/"
+ data_type
+ "_"
+ interval
+ "_metadata.csv"
)Data availability¶
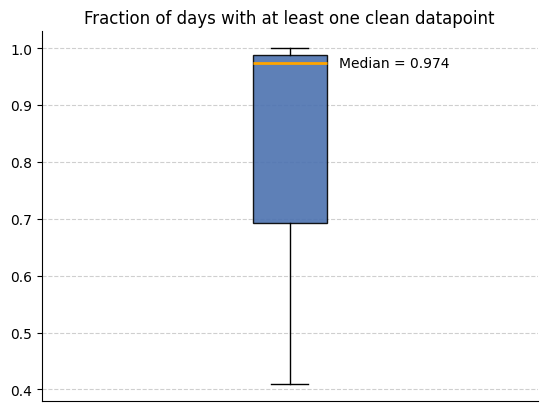
We can now use the metadata features we created to analyse how much data is available. We use the below code to look at the how many intervals (in this case days) have a non-zero amount of clean datapoints across all participants.
input_folder = output_folder # The folder that contains all the site subfolders with the cleaned data and metadata features
csv_name = "active_apple_healthkit_sleep_stage_D_metadata"
files_list = helper_funcs.get_file_paths(
input_folder, csv_name, Folder_structure=2, site_list=site_list
)
all_participants = []
for path in files_list:
df = pd.read_csv(path)
df["total clean datapoints"] = (
df["total counts"] - df["total timestamps with any error"]
)
all_participants.append(
1
- (
len(df[df["total clean datapoints"] == 0])
/ len(df["total clean datapoints"])
)
)
helper_funcs.draw_boxplot(df=all_participants, title="Fraction of days with at least one clean datapoint")3 files found